عضویت
عضویت ورود
ورود
برای افزایش امنیت هاست باید دو لایه همزمان پوشش داده شوند: آنچه «مشتری» در سطح دامنه/اپلیکیشن/حسابها انجام میدهد (SSL، بهروزرسانیها، دسترسیها، بکاپ، DNS/ایمیل)، و آنچه «شرکت هاستینگ» در زیرساخت انجام میدهد (سختگیری سیستمعامل، ایزولاسیون کاربران، WAF و محافظت DDoS، مانیتورینگ و پاسخ به رخداد). وقتی این دو لایه درست کنار هم بنشینند، ریسک نفوذ و داونتایم بهطور معنیدار کاهش مییابد.
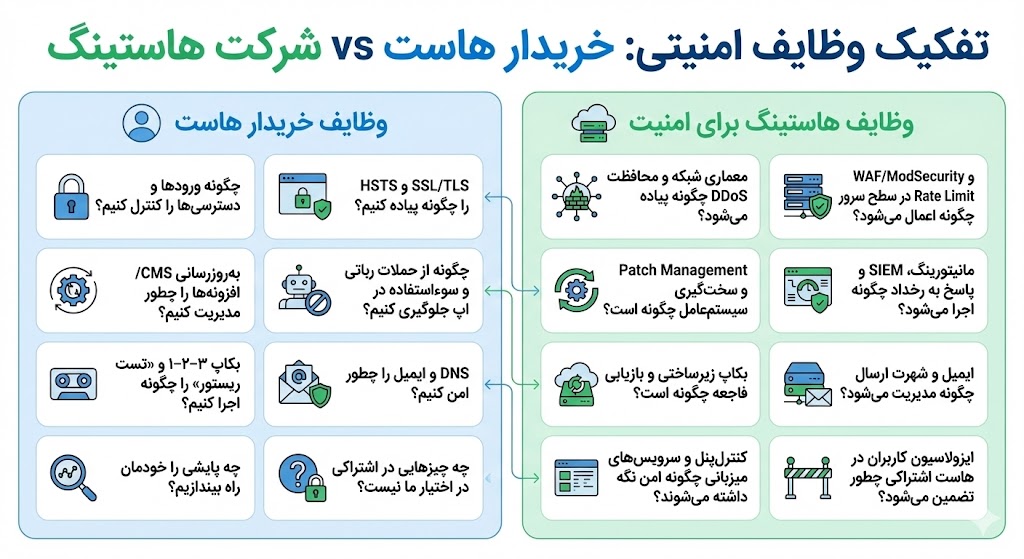
تفکیک وظایف امنیتی: خریدار هاست و شرکت هاستینگ
در این جدول، سرفصلهای اصلی اقدامات امنیتی به دو بخش تقسیم شدهاند: سمت چپ وظایف خریدار هاست و سمت راست وظایف هاستینگ برای امنیت.
| وظایف خریدار هاست | وظایف هاستینگ برای امنیت |
| چگونه ورودها و دسترسیها را کنترل کنیم؟ | معماری شبکه و محافظت DDoS چگونه پیاده میشود؟ |
| SSL/TLS و HSTS را چگونه پیاده کنیم؟ | WAF/ModSecurity و Rate Limit در سطح سرور چگونه اعمال میشود؟ |
| بهروزرسانی CMS/افزونهها را چطور مدیریت کنیم؟ | Patch Management و سختگیری سیستمعامل چگونه است؟ |
| چگونه از حملات رباتی و سوءاستفاده در اپ جلوگیری کنیم؟ | مانیتورینگ، SIEM و پاسخ به رخداد چگونه اجرا میشود؟ |
| بکاپ ۳–۲–۱ و «تست ریستور» را چگونه اجرا کنیم؟ | بکاپ زیرساختی و بازیابی فاجعه چگونه است؟ |
| DNS و ایمیل را چطور امن کنیم؟ | ایمیل و شهرت ارسال چگونه مدیریت میشود؟ |
| چه پایشی را خودمان راه بیندازیم؟ | کنترلپنل و سرویسهای میزبانی چگونه امن نگه داشته میشوند؟ |
| چه چیزهایی در اشتراکی در اختیار ما نیست؟ | ایزولاسیون کاربران در هاست اشتراکی چطور تضمین میشود؟ |
دسته اول: چه مواردی را باید خریدار هاست انجام دهد؟
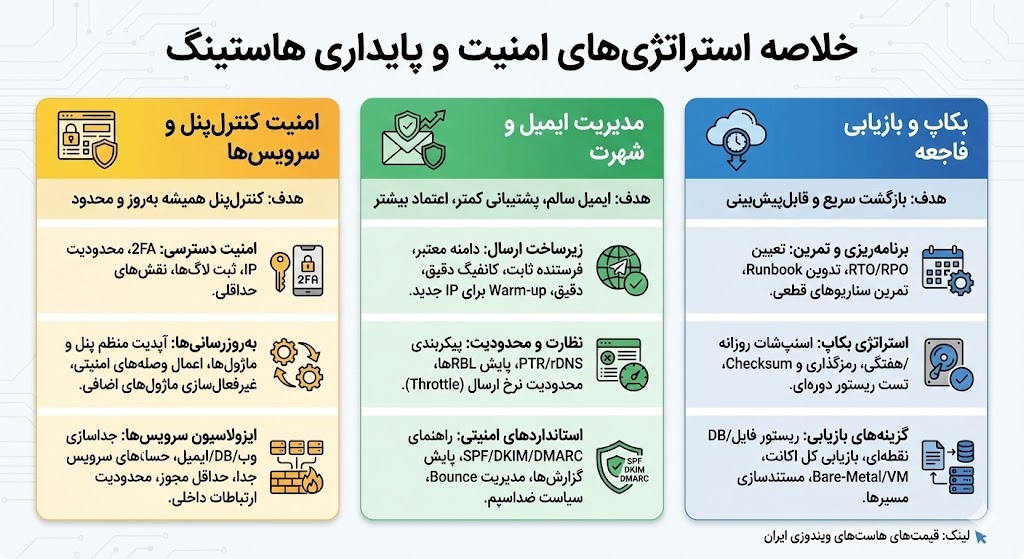
چگونه ورودها و دسترسیها را کنترل کنیم؟
اول هدف را روشن کنیم: هر درِ اضافهای که باز بماند، دیر یا زود دردسر میسازد. برای پنلهای مدیریت، CMS و ابزارهای ادمینی، اصلِ «کمترین دسترسی» را اجرا کن و ورود امن را اجباری کن تا فقط آدمهای درست، با حداقل اختیار لازم، وارد شوند.
-
فعالسازی 2FA روی همه پنلها و داشبوردها (ترجیحاً TOTP مثل Authenticator؛ اگر شد کلید سختافزاری).
-
نقشها و مجوزها را حداقلی تعریف کن؛ حسابهای بلااستفاده را سریع حذف یا غیرفعال کن.
-
اگر اپ اجازه میدهد، محدودسازی IP برای ناحیه ادمین بگذار و دسترسی عمومی را ببند.
-
نکته مهم: بستن «ورود روت» و تنظیم SSH کلیدمحور در VPS/اختصاصی انجام میشود؛ در هاست اشتراکی این بخش بر عهده هاستینگ است و با تیکت پیگیری میشود.
با همین چند اقدام ساده، سطح حمله بهطور محسوسی کوچک میشود و اگر هم رخدادی رخ دهد، دامنه آسیب محدود میماند.
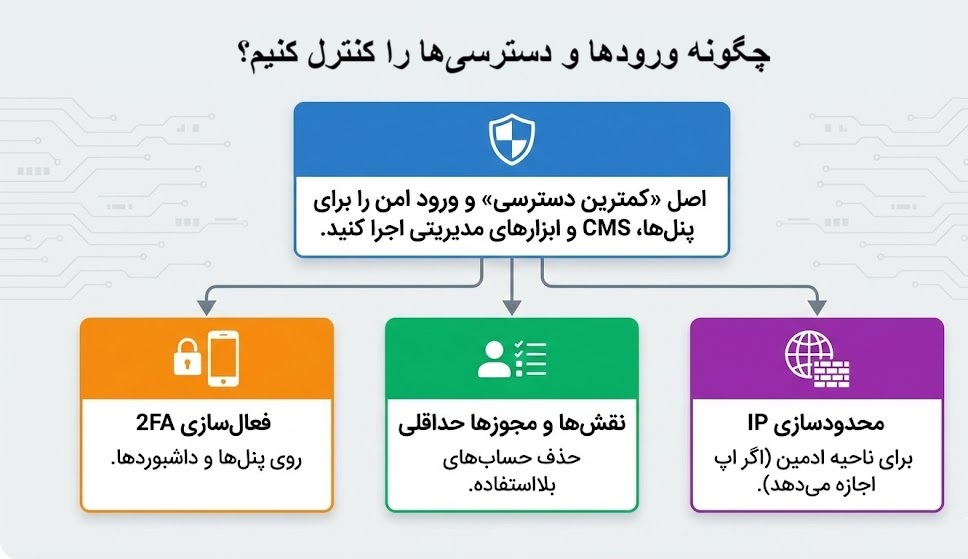
SSL/TLS و HSTS را چگونه پیاده کنیم؟
هدف ساده است: تمام ترافیک را امن، یکدست و بدون خطا کنید تا مرورگر هشدار ندهد، کاربر اعتماد کند و موتورهای جستجو سیگنال کیفیت بگیرند. اجرای درستِ HTTPS فقط نصب گواهی نیست؛ چند قدم کوچک اما مهم دارد.
-
تمام دامنهها/زیردامنهها را به HTTPS ببَر و خطاهای «محتوای مختلط» را صفر کن.
لینکها و اسکریپتهایhttp://را اصلاح کن (CSS/JS/تصویر/فونت). اگر سایت بزرگ است، از گزارش CSP یا گزینهٔupgrade-insecure-requestsکمک بگیر تا منابع ناامن شناسایی شوند. -
صدور خودکار Let’s Encrypt و ریدایرکت یکنواخت HTTP→HTTPS.
تمدید خودکار (Auto-Renew) را فعال کن، و ریدایرکت 301 را در یک نقطه (وبسرور/لبه) اعمال کن تا زنجیرهٔ ریدایرکت نسازی. نقشهسایت و Canonical را هم به نسخهٔ https بهروزرسانی کن. اگر زیردامنه زیاد داری، گواهی Wildcard با چالش DNS-01 بگیر. -
در صورت اطمینان از بینقصی HTTPS، HSTS را اضافه کن.
اول باmax-ageکوتاه شروع کن (مثلاً چند روز)، بعد به چند ماه افزایش بده؛ وقتی همهچیز پایدار شد، گزینههایincludeSubDomainsو در نهایت Preload را فعال کن. یادت باشد HSTS برگشتپذیری را سخت میکند—فقط وقتی مطمئن هستی روشنش کن. -
دورهای با ابزارهای تحلیل TLS، وضعیت را چک کن.
پروتکلها (TLS 1.3 روشن، 1.0/1.1 خاموش)، مجموعه رمزها، OCSP Stapling، و کاملبودن زنجیرهٔ گواهی را بسنج. ابزارهایی مثل SSL Labs بهت امتیاز و جزئیات عملی میدهند. برای اطمینان بیشتر، CAA بگذار تا فقط CAهای مجاز بتوانند گواهی صادر کنند.
جمعبندی کوتاه: HTTPS یکپارچه + ریدایرکت 301 تمیز + HSTS مرحلهای + پایش منظم TLS = حذف هشدارها، افزایش اعتماد و پایهٔ محکم برای سئو و تبدیل.
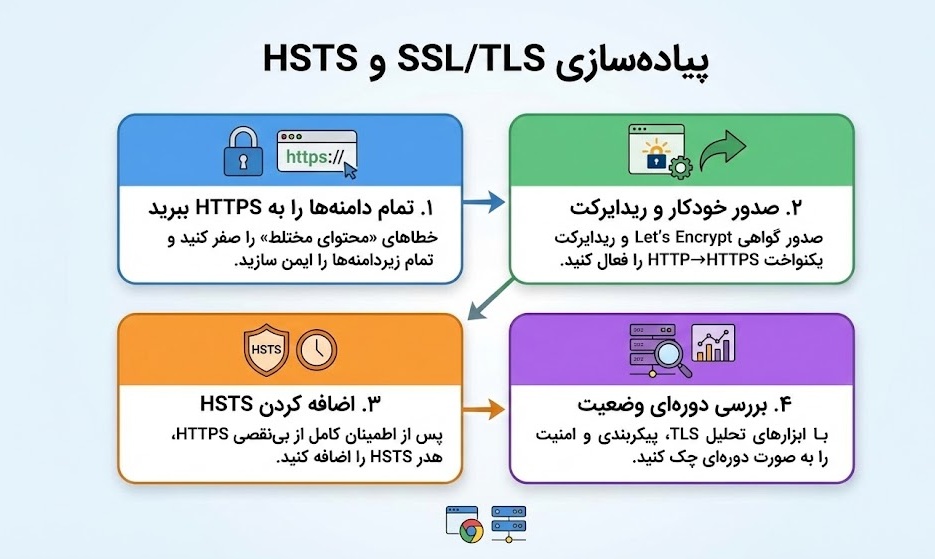
بهروزرسانی CMS/افزونهها را چطور مدیریت کنیم؟
قدیمیبودن نرمافزار بزرگترین ریسک امنیتی و عملکردی است؛ هر بهروزرسانیِ عقبافتاده یعنی یک درِ نیمهباز برای نفوذ، باگ، یا افت سرعت. راهحل مؤثر این است که برای هسته، قالبها و افزونهها یک «روال منظم و قابل پیشبینی» داشته باشی و تغییرات مهم را همیشه اول در محیط آزمایشی (Staging) امتحان کنی.
روال پیشنهادی (کوتاه و عملی):
-
برنامه منظم بچین: هسته، قالبها و افزونهها را نظممند بهروز کن (پچهای امنیتی سریع؛ نسخههای اصلی پس از تست).
-
تمیزکاری قبل از آپدیت: افزونههای بلااستفاده را حذف و در صورت نیاز جایگزینهای معتبر انتخاب کن.
-
اول Staging، بعد تولید: تغییرات مهم را اول در Staging امتحان کن؛ سناریوهای حیاتی (ورود، سبد خرید، فرمها) را تست بزن.
-
بکاپ مطمئن بگیر: قبل از اعمال در سایت اصلی، بکاپ کامل فایل+دیتابیس داشته باش و ریستور آزمایشی را حداقل ماهانه انجام بده.
-
پایش پس از انتشار: بعد از بهروزرسانی، خطاهای 5xx/JS، TTFB و نرخ تبدیل را رصد کن و در صورت مشکل، سریع Rollback کن.
نکتههای تکمیلی برای دردسر کمتر:
-
ترتیب بهروزرسانی را رعایت کن: اول هسته، بعد افزونهها، سپس قالب.
-
باگهای شناختهشده را از لاگ تغییرات (Changelog) بخوان؛ اگر وصله امنیتی است، تعلل نکن.
-
نسخه PHP/ماژولها را با سازگاری قالب/افزونهها چک کن تا غافلگیر نشوی.
-
برای پروژههای بزرگ، بخشی از آپدیتها را خودکار کن (فقط پچهای امنیتی) و انتشارهای اصلی را دستی و مرحلهای انجام بده.
بیشتر بخوانید: راهنمای خرید هاست لینوکس
چگونه از حملات رباتی و سوءاستفاده در اپ جلوگیری کنیم؟
اول اصل را رعایت کن: درِ ورودی اپ را شلوغ نگذار. یعنی فقط ترافیکِ لازم را راه بده، بقیه را هوشمندانه کند یا متوقف کن تا هم امنیت بالا برود، هم UX خراب نشود.
-
Rate Limit و reCAPTCHA برای مسیرهای ورود/ثبتنام/فرمها.
محدودسازی را بر اساس «کاربر/IP/اندپوینت» و بهصورت Burst+Sustained تنظیم کن؛ چالش را فقط در رفتار مشکوک فعال کن تا کاربر سالم اذیت نشود. برای محافظت سراسری، همین قواعد را در لبه (WAF/CDN) هم اعمال کن. -
بستن/محدود کردن XML-RPC و APIهای کماستفاده.
هر اندپوینتی که نیاز نداری را خاموش کن؛ اگر لازم است بماند، حداقل با IP Allowlist، کلیدهای چرخشی و نرخسنجی (Throttle) محافظتش کن. وبهوکها و درگاههای پرداخت را حتماً در Allowlist بگذار. -
لاگگیری و هشدار روی تلاشهای ورود ناموفق.
شمارندهٔ شکست ورود را نگه دار، پس از چند بار شکست، Backoff/Lockoutِ زماندار اعمال کن و هشدار بلادرنگ بفرست. الگوهای غیرعادی (افزایش ناگهانی 401/429، نرخ کپچای حلنشده) را هم مانیتور کن.
نکتهٔ مهم: بستن «ورود روت» و تنظیم SSH کلیدمحور در VPS/اختصاصی و سرور اختصاصی انجام میشود؛ در هاست اشتراکی این بخش با هاستینگ است و باید از پشتیبانی بخواهی.
چند تکمیلکننده سبک ولی مؤثر:
-
فیلد Honeypot نامرئی برای فرمها، تأیید ایمیل/موبایل در ثبتنام، و محدودکردن تلاشهای Reset Password.
-
توکنهای CSRF و کوکیهای
SameSite=Strictبرای همه فرمهای حساس. -
گزارش هفتگی از متریکها: Failed Logins، نرخ 429، صفحات هدف حمله و IP/ASNهای پرتکرار—و بهروزرسانی دورهای قوانین بر اساس همین دادهها.
با همین ترکیب ساده (Rate Limit هوشمند، قفلکردن ورودیهای کممصرف، و پایش فعال)، سطح حمله کوچک میشود و سوءاستفاده قبل از تبدیل شدن به داونتایم یا نشت داده متوقف خواهد شد.
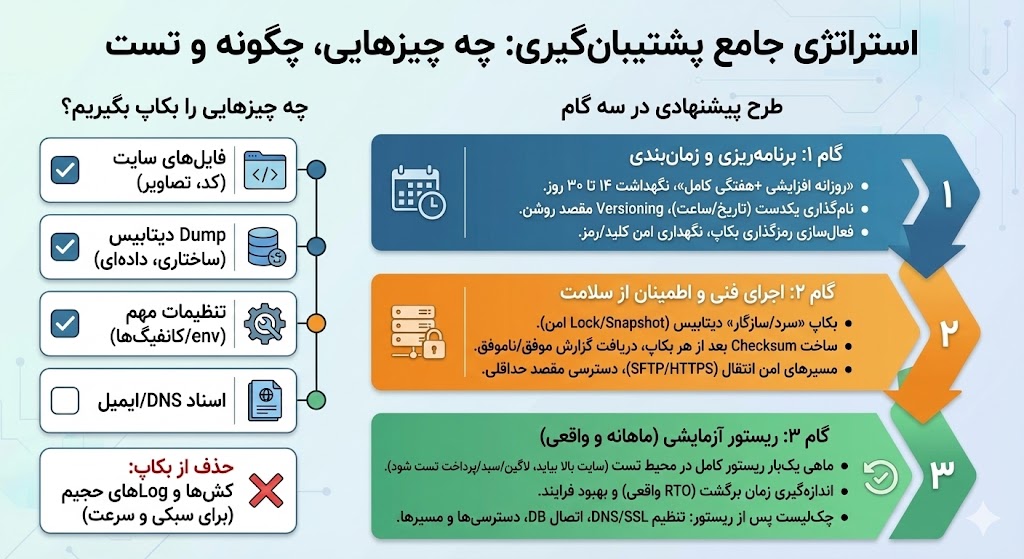
بکاپ ۳–۲–۱ و «تست ریستور» را چگونه اجرا کنیم؟
«بکاپ بدون ریستورِ تستشده، بکاپ نیست.» هدف این است که در بدترین روز، سریع و مطمئن برگردی. الگوی ۳–۲–۱ یعنی سه کپی از دادهها، روی دو رسانه متفاوت، و حداقل یک نسخه خارج از سرور (S3/FTP/Cloud). کنار این، باید بدانی تا چه حد داده از دست میدهی (RPO) و در چند دقیقه/ساعت برمیگردی (RTO).
چه چیزهایی را بکاپ بگیریم؟
فایلهای سایت، Dump دیتابیس، تنظیمات مهم (env/کانفیگها)، اسناد DNS/ایمیل. کشها و Logهای حجیم را از بکاپ حذف کن تا نسخهها سبک و سریع بمانند.
طرح پیشنهادی در سه گام
-
برنامهریزی و زمانبندی
-
«روزانه افزایشی + هفتگی کامل» را اجرا کن؛ نگهداشت ۱۴ تا ۳۰ روز منطقی است.
-
نامگذاری نسخهها یکدست باشد (تاریخ/ساعت)، و روی مقصدِ خارج از سرور Versioning روشن باشد.
-
رمزگذاری بکاپ را فعال کن و برای هر مقصد، کلید/رمز را امن نگه دار.
-
اجرای فنی و اطمینان از سلامت
-
برای دیتابیس، بکاپ «سرد/سازگار» بگیر (Lock یا Snapshot امن).
-
بعد از هر بکاپ، Checksum بساز و گزارش موفق/ناموفق بگیر.
-
مسیرهای انتقال را امن کن (SFTP/HTTPS)، دسترسی مقصد را حداقلی نگه دار.
-
ریستور آزمایشی (ماهانه و واقعی)
-
ماهی یکبار روی محیط آزمایشی ریستور کامل انجام بده؛ سایت بالا بیاید، لاگین/سبد/پرداخت تست شود.
-
زمان «برگشت» را اندازه بگیر (RTO واقعی) و اگر طولانی است، فرایند یا ابزار را بهبود بده.
-
چکلیست پس از ریستور داشته باش: تنظیم DNS/SSL، اتصال DB، دسترسیها و مسیرها.
اشتباهات رایج که باید از آنها دوری کنی
-
اعتماد به «بکاپ روی همان سرور» (ریسک از دست رفتن همزمان).
-
نداشتن گزارش و هشدار؛ یک بکاپ شکستخورده بیخبر.
-
نگهداشت بسیار کوتاه یا بسیار بلند (هزینه/ریسک را متعادل کن).
-
ریستور نکردنِ نسخهها؛ فقط «گرفتن بکاپ» کافی نیست.
چکلیست یکدقیقهای
-
سه کپی، دو رسانه، یک نسخه بیرون از سرور ✔️
-
روزانه افزایشی + هفتگی کامل + نگهداشت ۱۴–۳۰ روز ✔️
-
حذف کش/لاگ، رمزگذاری و Checksum ✔️
-
گزارش خودکار موفق/ناموفق و هشدار فوری ✔️
-
ریستور آزمایشی ماهانه با سنجش RTO/RPO ✔️
با این روال ساده و مستمر، در بحرانها ضرر را محدود میکنی و با اطمینان به وضعیت عادی برمیگردی.
DNS و ایمیل را چطور امن کنیم؟
شناسهٔ دامنه و ایمیل، هدف رایج حملاتاند؛ با این چند قدم ساده اما ضروری، ریسک را بهطور محسوس کم کن.
-
SPF/DKIM/DMARC را تنظیم کن.
دقیقاً طبق مقادیر پیشنهادی هاستینگ رکوردها را بساز تا جعل هویت سخت شود و تحویلپذیری ایمیل بالا برود. -
DNSSEC و CAA را فعال کن (در صورت پشتیبانی).
DNSSEC زنجیرهٔ اعتماد DNS را امضا میکند؛ CAA هم صادرکنندههای مجاز SSL را محدود میکند تا گواهیِ ناخواسته صادر نشود. -
ایمیل مالک دامنه را مستقل نگه دار + 2FA.
ایمیل مالک روی همان دامنه نباشد (برای روزهای اختلال/انقضا گیر نیفتی) و روی رجیسترار/پنلها احراز دومرحلهای را روشن کن. -
بعد از هر تغییر، تست و پایش داشته باش.
یک ایمیل آزمایشی به Gmail/Outlook بفرست، هدرها را بررسی کن و صحت رکوردها را با ابزارهای DNS چک کن.
بیشتر بخوانید: چگونه هاست وردپرس بخریم؟
چه پایشی را خودمان راه بیندازیم؟
هدف این است که «زود بفهمیم و سریع واکنش بدهیم»؛ هر دقیقه تأخیر یعنی ریسک بیشتر و هزینه بالاتر.
-
به هشدارِ زودهنگام تکیه کن.
برای سرویسهای حیاتی (صفحه اصلی، ورود، پرداخت) چکهای جدا بگذار؛ آستانهها را واقعبینانه تنظیم کن و فقط به “میانگین” بسنده نکن—p95/p99 را هم پایش کن. -
مانیتورینگ Uptime/5xx/TTFB از چند نقطه.
سنجش بیرونی از چند شهر/کشور انجام بده تا تصویر واقعی کاربر را ببینی. TTFB را جدا برای صفحات کلیدی اندازه بگیر و جهشهای 5xx را ثبت کن تا با انتشارها/تغییرات همبازخوانی شود. -
هشدار فوری ایمیل/تلگرام و برنامه پاسخ به رخداد (چه کسی، چه کاری، در چند دقیقه).
یک کانال واحد برای آلارمها تعیین کن، شدتبندی (Severity) داشته باش و Runbook بنویس: نفر مسئول، اقدام اول، زمانبندی Escalation و معیار پایان رخداد.
دو افزودنی سبک ولی مؤثر:
-
پایش انقضای SSL/DNS و اعلان تغییر رکوردهای حساس.
-
گزارش هفتگی روندها با یادداشتِ تغییرات (Release Notes) برای ریشهیابی سریع.
چکلیست ۳۰ ثانیهای: Uptime/5xx/TTFB چندمنطقهای ✔️ | کانال هشدار + Runbook روشن ✔️ | گزارش روندها + پایش SSL/DNS ✔️
چه چیزهایی در اشتراکی در اختیار ما نیست؟
در هاست اشتراکی به سیستمعامل و تنظیمات سراسری دسترسی نداری؛ پس بعضی کارها «ذاتاً» خارج از اختیار توست و فقط باید از پشتیبانی بخواهی انجامشان دهد.
-
شفاف بدان کجا خط قرمز توست: anything سطح سرور/سیستمعامل، تنظیمات شبکهٔ نود و امنیت لبه.
-
فایروال نود، SSH سراسری، بستن روت، ModSecurity سروری و سختگیری کرنل را هاستینگ انجام میدهد (همراه با بهروزرسانیهای OS/Web/PHP و ایزولاسیون کاربران).
-
در این موارد فقط درخواست/تیکت و پیگیری کن: باز/بستن پورتها، اعمال/تیون قوانین WAF، محدودیت نرخ در لبه، تغییر نسخههای سراسری PHP/DB، فعالسازی DNSSEC/CAA در رجیسترارِ متصل، و سیاستهای بکاپ زیرساختی.
نکتهٔ عملی: تو روی لایهٔ اپلیکیشن تمرکز کن (SSL، 2FA، نقشها، کش، بهروزرسانیها، SPF/DKIM/DMARC) و هر چیزی که «بوی سیستمعامل/شبکه» میدهد را با تیکت از هاستینگ بخواه.
دسته دوم: چه کارهایی باید شرکت هاستینگ انجام دهد؟
معماری شبکه و محافظت DDoS چگونه پیاده میشود؟
هدف این لایه، «تابآوری زیرساخت» است؛ یعنی حتی زیر حمله یا خطای بخشی از شبکه، سرویس در دسترس بماند و کاربر افت محسوسی حس نکند.
-
زیرساخت باید تابآور باشد.
از ابتدا برای خرابی برنامهریزی کن: ظرفیت مازاد لینکها، مسیرهای جایگزین، و حذف نقاط تکخرابی (Single Point of Failure). نگهداریها را بدون قطعی (rolling) انجام بده و سناریوهای بحران را از قبل تمرین کن. -
سگمنتبندی شبکه (Public/Private/DMZ) و مسیرهای مستقل.
لایه کاربر (Public)، لایه اپ/وب (DMZ) و لایه دیتابیس/مدیریت (Private) را با VLAN/VXLAN جدا کن؛ میان سگمنتها فایروال stateful و ACL دقیق بگذار. ترافیک مدیریتی را روی مسیر و رابط جدا (out-of-band) نگه دار. برای شرق–غرب (East-West) هم ریزبخشی (Microsegmentation) داشته باش تا نفوذ محدود بماند. -
محافظت DDoS لایه 3/4/7 و در لبه، ترجیحاً Anycast.
سپر همیشهفعال در لایه شبکه/انتقال (فیلتر حملات حجمی، SYN/UDP Flood) و در لایه اپ (WAF برای HTTP/HTTPS). Anycast ترافیک را به نزدیکترین مراکز پاکسازی پخش میکند تا ظرفیت جذب بالا برود. قواعد Rate Limit، Challenge/Bot Management و امضای OWASP CRS را بهروز نگه دار. در سناریوهای شدید، BGP Redirect به مرکز Scrubbing و در بدترین حالت RTBH بهصورت کنترلشده. -
Health-check و Failover خودکار.
برای هر سرویس، سلامتسنجی دورهای (HTTP/TCP) داشته باش و با Load Balancer/DNS Failover بین نودها/مراکز جابهجا شو. معماری Active-Active یا Active-Passive را بر اساس نیاز انتخاب کن، با RTO/RPO مشخص و Runbook روشن برای برگشت. تستهای منظم سوییچاُور (Game Day) فراموش نشود.
چند نکته اجرایی تکمیلی:
-
ظرفیتسنجی پیوسته (Capacity Planning) و مانیتورینگ چندمنطقهای Uptime/Latency/5xx.
-
لاگ و تلهمتری شبکه (Flow/Netflow) و داشبورد بلادرنگ برای تشخیص الگوهای حمله.
-
کنترل تغییرات (Change Management) و استقرار تدریجی تا خطاها به کل شبکه سرایت نکنند.
با این چیدمان، شبکه نهتنها سریع و امن میماند، بلکه زیر بار حملات و خطاها هم «پایدار» عمل میکند.
WAF/ModSecurity و Rate Limit در سطح سرور چگونه اعمال میشود؟
هدف این لایه، فیلتر هوشمند ترافیک قبل از رسیدن به اپ است تا بارِ اضافی و درخواستهای مخرب حذف شوند و UX پایدار بماند.
-
قوانین OWASP CRS بهروز، Bot Management و استثناهای امن (Allowlist) برای درگاهها. مجموعه قوانین را مرتب بهروزرسانی کن، برای رفتار رباتی Challenge/CAPTCHA هدفمند بگذار و IP/دامنههای ضروری (درگاه پرداخت، وبهوکها) را در Allowlist نگه دار.
-
Rate Limit تطبیقی روی مسیرهای ورود/ثبتنام/جستوجو/API: الگوی Burst + Sustained تا هم سوءاستفاده مهار شود و هم کاربر واقعی متوقف نشود.
-
گزارش Hit/Miss و تیون مستمر. خطاهای مثبت کاذب را بر اساس لاگها اصلاح کن، قوانین اختصاصی برای مسیرهای پرترافیک بنویس و هر انتشار (Release) را با گزارش WAF تطبیق بده.
Patch Management و سختگیری سیستمعامل چگونه است؟
اصل راهبردی این است: درِ حمله را از ریشه ببند. یعنی سطح سیستمعامل و سرویسهای پایه را همیشه سالم و بهروز نگه دار.
-
بهروزرسانی کرنل/کتابخانهها، SSH سختگیرانه، خاموشکردن سرویسهای غیرضروری.
PermitRootLogin no، محدودکردن Auth، Fail2ban/فایروال فعال، و حداقلنصب (Minimal Packages) تا سطح حمله کوچک بماند. -
پروفایلهای امن برای Web/PHP/DB و سیاست نسخهها. نسخههای پشتیبانیشده، ماژولهای لازم فقط، محدودکردن توابع خطرناک در PHP، کاربر/مجوز جداگانه برای هر دیتابیس و Cipherهای مدرن (TLS 1.3).
-
مدیریت وصله با برنامه و ابزار. پنجره نگهداری، ثبت تغییرات، اسکن دورهای آسیبپذیری و جلوگیری از Drift (مثلاً با Ansible) تا سازگاری محیطها حفظ شود.
مانیتورینگ، SIEM و پاسخ به رخداد چگونه اجرا میشود؟
بدون دیدِ 24×7 و اقدام سریع، بهترین تنظیمات هم دیر به کمک میآیند.
-
پایش دقیقهای Uptime/Latency/5xx از چند منطقه. چکهای HTTP/TCP چندنقطهای، سنجش TTFB/LCP صفحات کلیدی و آستانههای هشدار واقعبینانه (میانگین و p95/p99).
-
تجمیع لاگ در SIEM و Runbook Incident با SLA روشن. لاگهای وب/WAF/سیستمعامل/دیتابیس را متمرکز کن، قوانین همبستگی (Correlation) بگذار و مسیر اقدام مرحلهای بنویس: چه کسی، چه کاری، در چند دقیقه.
-
پسارخداد و مانور. گزارش علت ریشهای (RCA)، اقدام اصلاحی، و مانور دورهای Failover/حمله سازیشده تا تیم در شرایط واقعی غافلگیر نشود.
بکاپ زیرساختی و بازیابی فاجعه چگونه است؟
هدف این لایه ساده است: حتی در بدترین سناریو، سرویس «سریع و قابلپیشبینی» برگردد.
-
وقتی بدترین اتفاق افتاد، سریع برگرد. RTO/RPO مشخص کن، Runbook عملیاتی بنویس (چه کسی، چه کاری، در چند دقیقه) و سناریوهای قطعِ بخشبهبخش را از قبل تمرین کن.
-
اسنپشات/آفسایت منظم، Retention شفاف و تستهای دورهای ریستور. روزانه افزایشی + هفتگی کامل، رمزگذاری و Checksum، نگهداشت نسخهها با سیاست روشن، و ریستور آزمایشی زمانسنجیشده.
-
گزینههای ریستور در سطوح مختلف (فایل، دیتابیس، کل اکانت). امکان ریستور نقطهای فایل/DB، بازیابی Full Account و در لایهٔ زیرساخت، Bare-Metal یا ماشینِ مجازی؛ مسیرهای بازگشت را مستندسازی کن.
بیشتر بخوانید: قیمتهای هاستهای ویندوزی ایران
ایمیل و شهرت ارسال چگونه مدیریت میشود؟
ایمیل سالم، بارِ پشتیبانی را کم و اعتماد کاربر را زیاد میکند.
-
ایمیل سالم = پشتیبانی کمتر. تحویلپذیری خوب یعنی کمتر تیکت «ایمیلم نرسید»؛ فرستندهٔ ثابت، دامنه معتبر و کانفیگ دقیق، کلید ماجراست.
-
پیکربندی PTR/rDNS، نظارت بر RBLها، محدودیت نرخ ارسال. IP با PTR درست، مانیتورینگ لیستهای سیاه، Queue سالم، Throttle بر اساس کاربر/دامنه، و Warm-up برای IP جدید.
-
ارائه راهنمای دقیق SPF/DKIM/DMARC به مشتری. مقادیر پیشنهادی و پایش گزارشهای DMARC؛ تفکیک Bounceها، استفاده از Postmaster Tools و سیاست ضداسپم شفاف.
کنترلپنل و سرویسهای میزبانی چگونه امن نگه داشته میشوند؟
کنترلپنل نقطهٔ حساس مدیریت است؛ باید همیشه بهروز و محدود باشد.
-
ابزارها باید امن بمانند. دسترسی پنل را با 2FA و محدودیت IP محافظت کن؛ لاگهای ورود/تغییر را نگه دار و نقشها را حداقلی تعریف کن.
-
بهروزرسانی DirectAdmin/cPanel و ماژولها. وصلههای امنیتی پنل و افزونهها را بهموقع اعمال کن، ماژولهای بلااستفاده را غیرفعال و نسخهها را استاندارد کن.
-
جداسازی سرویسها (وب/DB/ایمیل) و محدودسازی دسترسیهای داخلی. حسابهای سرویس جدا، حداقل مجوز، ایزولاسیون پردازهها و محدودیت ارتباطات داخلی؛ هر سرویس فقط به منابع ضروری دسترسی داشته باشد.